
One approach to problem-solving is to use a program to find the optimized solution. This applies broadly. For example, your problem might be finding the lowest cost location to build a distribution center (DC), finding the right people to add to your team/company, or determining how to get to the local Target. When systems create solutions, they tend to focus on optimizing something. In the case of routing, they tell us the shortest path (minimize distance), the fastest way (minimize time), or the path that avoids highways (minimize high-speed roads). There is almost always an “answer”. A system will almost always produce a strict set of instructions to get the user from point A to point B (and a lot of the time it works well enough we think). To me, that’s too rigid for some routing problems. At times we want guidance rather than strict instruction.
In these cases, we may want to be given a North Star (approximately which direction we should go) and have supervision to that North Star… but we may also want to bake in our own creativity and keep open the possibility of discovering something that no one else has. As an analogy, Derek Sivers wrote about the balance between no guidelines and following tradition when creating music. No guidelines, he writes, is “anti-inspiring because having infinite options is overwhelming.” Too many options are paralyzing. Conversely, Sivers writes, “stay[ing] within the guidelines of a genre or style [is] too strict and sad.” In-between these two extremes is his optimal and gives me a good foundation for how to approach route planning for running.
Preserving optionality is: “a strategy of keeping options open and fluid, fighting the urge to make choices too soon, before all of the uncertainties have been resolved”. I believe that if we can intertwine this concept of preserving optionality with optimal routing we may be able to pave the way for innovative routing algorithms. When I go out running I know several things. A) I typically want to start and end at the same location. B) I want to run X number of miles. C) I want a general direction I should run in (my North Star). D) I like variety… if I feel like going down a certain path on a certain day that freedom can be motivating. If I was to find the “optimal” route based on data every time I stepped into the world, it would rob me of part D (and likely some of part C). Steve Jobs talked about the invisible dots… going after the right direction and believing the dots are appearing and connecting as you go – you need the flexibility to follow your “hell yeahs” while also having a high-level vision.
Perhaps the biggest reason to balance optionality and optimization in route planning is the pervasive fact that data contains noise and imperfect information. For example, map data (or most of the map data that you have access to) doesn’t get updated as frequently as the real world. Roads/trails come and go, but your data persists. Beyond that, the level of granularity you may need probably doesn’t exist. A trail isn’t always just a trail. Sometimes it’s sandy, rocky, rooty, or flooded… but your map data just says “trail.” If we put these ideas together we start thinking about the overlap between noisy data, desire for efficiency, and emotional entropy. We want data-driven decision making & optimality in our lives, but we also want creativity, surprise, and wonder. In route planning (a data-supported problem), we too frequently let the algorithm tell us the optimal way and are disappointed when that way doesn’t feel optimal. An alternative approach when planning running routes is to let clusters of ‘good running hotspots’ be your North Star and leverage randomness to guide you there.
The collaborative project OpenStreetMap provides us with a rich data source of tagged geospatial data. For example, looking in an OSM file from my hometown I see that one of the local trails is marked with the tag v=”path”. This is part of the VA Woods trail system that I run nearly every time I am back in this area.
There are several of those keywords in the OSM data that we can use to positively identify clusters of good running features. These are a few of the keywords we can use to identify where these clusters exist…
keywords = ['foot', 'checkpoint', 'historic', 'path', 'hiking']
We can do some filtering and manipulation of the data to obtain all the nodes and edges as well as their latitude-longitude coordinates that we might consider premium for running. Then, we can use Leaflet to plot these on a map (note that I used the Leaflet package in R, but the Folium package in Python). Leaflet is ideal for prototyping this since it has a clustering feature which will group clusters of points depending upon your level of zoom. When I do that for my hometown – assuming I am starting a run from East Northport Middle School (11731 NY) – I can see several dense clusters of good running features.
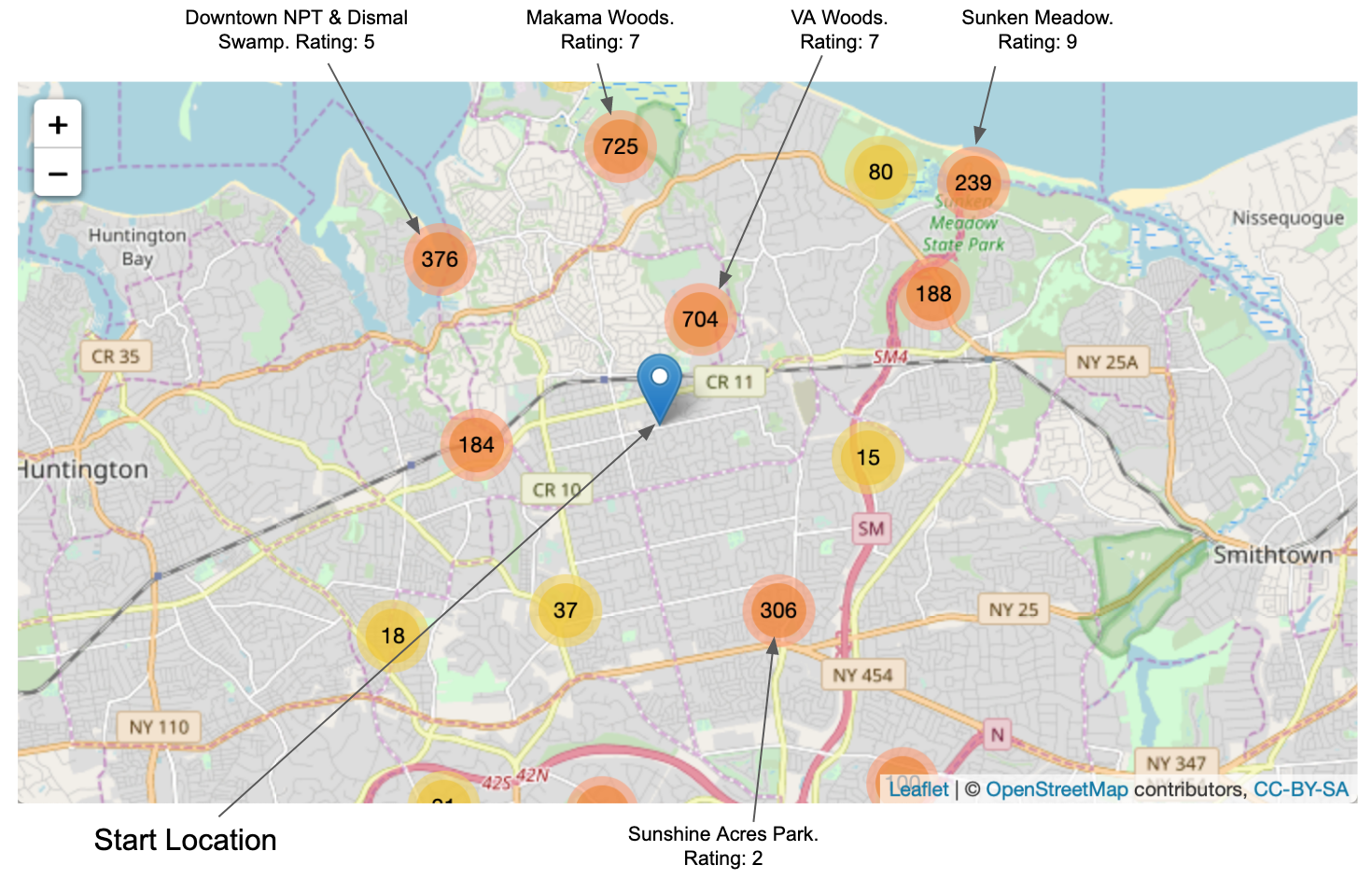
Since this is my hometown and I’ve done lots of mileage here, I know that if I want a quality 10-15 mile run I should go to Sunken Meadow… if I want a quality 5-10 mile run I should go to Makama… and if I want a quality 0-5 mile run I should go to the VA Woods. While these guidelines aren’t strictly true, they do provide me with that figurative North Star. Then, it’s up to me (or my application) to guide myself toward that North Star improving when and where I see fit. If I’m designing an algorithm I could use a random element to interject variety into the route recommendation.
Now it seems like this is problem solved. We pull the data, we find the clusters, we let the user determine the path to the cluster and back from it. But, there is a really big next step here. These clusters (or North Stars) really only work under the right conditions – during the day and with limited weather. There are a number of reasons I’ve experienced over the years why the best route as determined from tagged data might instantly not be the best route when a runner starts her run….
- Weather. Rain may have destroyed certain trails. Snow may be covering a route that’s great in the summer. In this case, you probably prefer a plowed road.
- Time of Day. The best trails are the best trails in the day. In the extremely early in the morning or late at night (or not that late but you live in Minneapolis and it’s winter), you perhaps want the best lit or safest route – roads with wide shoulders or sidewalks.
- Traffic. At rush hour, the best route may actually be the worst if you have to wait for traffic lights or risk getting hit by a car.
- Road Conditions. Roads and bridges are often closed for repair. This isn’t typically reflected in our data.
- Serendipity. Sometimes I like to run past the homes of friends or family on the off chance they are outside and I can say hi. It feels good.
This means routes need to be pretty adaptable to real-time uncertainty. Depending upon conditions, not only does the path to the cluster need to adapt, but those clusters themselves need to change. That will include not only adjusting the keywords but also using complementary data sets about the area. Back to my hometown, for example, if I am in a mood to see people I am likely going to head for downtown Northport (not the woods) where shops and parks are dense. On the map above, the rating is a 5 for that area… but in this emotional state, it’s more like a 9. At the same time, it’s more dangerous because there are more cars. These individual preferences that change across time need to be considered. When the environment changes (i.e. external conditions or internal sentiments), how do our algorithms respond?
There is a life lesson here. Data-driven is only as good as how driven we are to make a decision in a given moment. There is rarely a strict answer for complex problems and you will continue to need to balance noisy data, desire for efficiency, and emotional entropy. Consider confidence intervals. We should always be willing to accept that our data-derived answer has flaws. Whether you are making decisions about where to build a DC, who to hire (or fire), or which route you should take to Target… data can be part of the answer but the decision should be made by you.
To help others recreate this map, I’ve posted this gist on Github.